Introduction
The Semantic Domain Working Group defines the data entry and data capture elements within a decentralized digital network so that inputs from assured sources can always be trusted and the meaning of data elements is maintained throughout every exchange.
Data capture, specifically, is the process of collecting data electronically, allowing it to be stored, searched, or organised more efficiently. In a decentralised network, data capture requires the provision of immutable fields in order to capture and store collected data.
The diagram depicts these elements and characteristics as the (lower) Semantic domain:
Semantic domain [passive] / the meaning and use of what is put in, taken in, or operated on by any process or system.
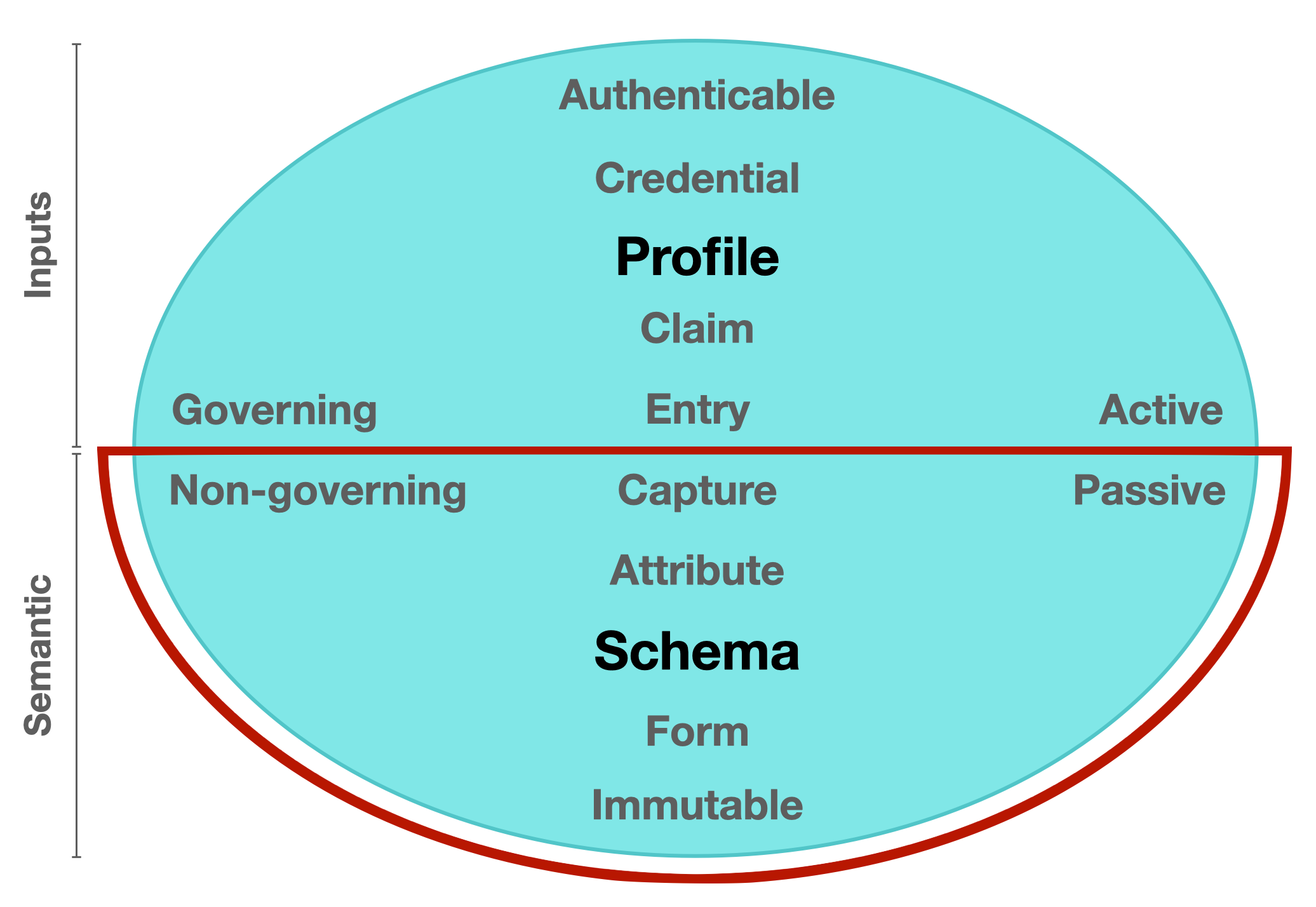
Figure. A component diagram showing the inputs and semantic counterparts of a balanced network model.
Scope
Define a data capture architecture consisting of immutable schema bases and interoperable overlays for Internet-scale deployment. The scope of the WG is to define specifications and best practices that bring cohesion to data capture processes and other Semantic standards throughout the ToIP stack, whether these standards are hosted at the Linux Foundation or external to it. Other WG activities will include creating template Requests for Proposal (RFPs) and additional guidance to utility and service providers regarding implementations in this domain. This WG may also organise Task Forces to escalate the development of certain components if deemed appropriate by the majority of the WG members and in line with the overall mission of the ToIP Foundation.
Meetings
Schedule:
US/EU: meetings take place weekly on a Tuesday from 09:00-10:00 US PT, 12:00-13:00 US ET, 16:00-17:00 UTC
APAC: TBC
See the Meeting Page for Agendas, notes and recordings from all meetings.
Deliverables
- Technical specifications for all core components required within the Semantic domain
Chairs / Leads
How to join
You can join this WG by signing up for the Foundation mailing list at lists.trustoverip.org. Our mailing list is semantic-domain-wg@lists.trustoverip.org.
Members as well as observers are welcome (with the important caveat below).
Participation
For the protection of all Members, participation in working groups, meetings and events is limited to members, including their employees, of the Trust over IP Foundation who have signed the membership documents and thus agreed to the intellectual property rules governing participation. If you or your employer are not a member, we ask that you not participate in meetings by verbal contribution or otherwise take any action beyond observing.
Core concepts
Context
The post millennial generation has witnessed an explosion of captured data points which has sparked profound possibilities in both Artificial Intelligence (AI) and Internet of Things (IoT) solutions. This has spawned the collective realization that society’s current technological infrastructure is simply not equipped to fully support de-identification or to entice corporations to break down internal data silos, streamline data harmonization processes and ultimately resolve worldwide data duplication and storage resource issues. Developing and deploying the right data capture architecture will improve the quality of externally pooled data for future AI and IoT solutions.
Overlays Capture Architecture (OCA)
(Presentation and live demo / Tools tutorial / .CSV parsing tutorial)
OCA is an architecture that presents a schema as a multi-dimensional object consisting of a stable schema base and interoperable overlays. Overlays are task-oriented linked data objects that provide additional extensions, coloration, and functionality to the schema base. This degree of object separation enables issuers to make custom edits to the overlays rather than to the schema base itself. In other words, multiple parties can interact with and contribute to the schema structure without having to change the schema base definition. With schema base definitions remaining stable and in their purest form, a common immutable base object is maintained throughout the capture process which enables data standardization.
OCA harmonizes data semantics. It is a global solution to semantic harmonization between data models and data representation formats. As a standardized global solution for data capture, OCA facilitates data language unification, promising to significantly enhance the ability to pool data more effectively for improved data science, statistics, analytics and other meaningful services.
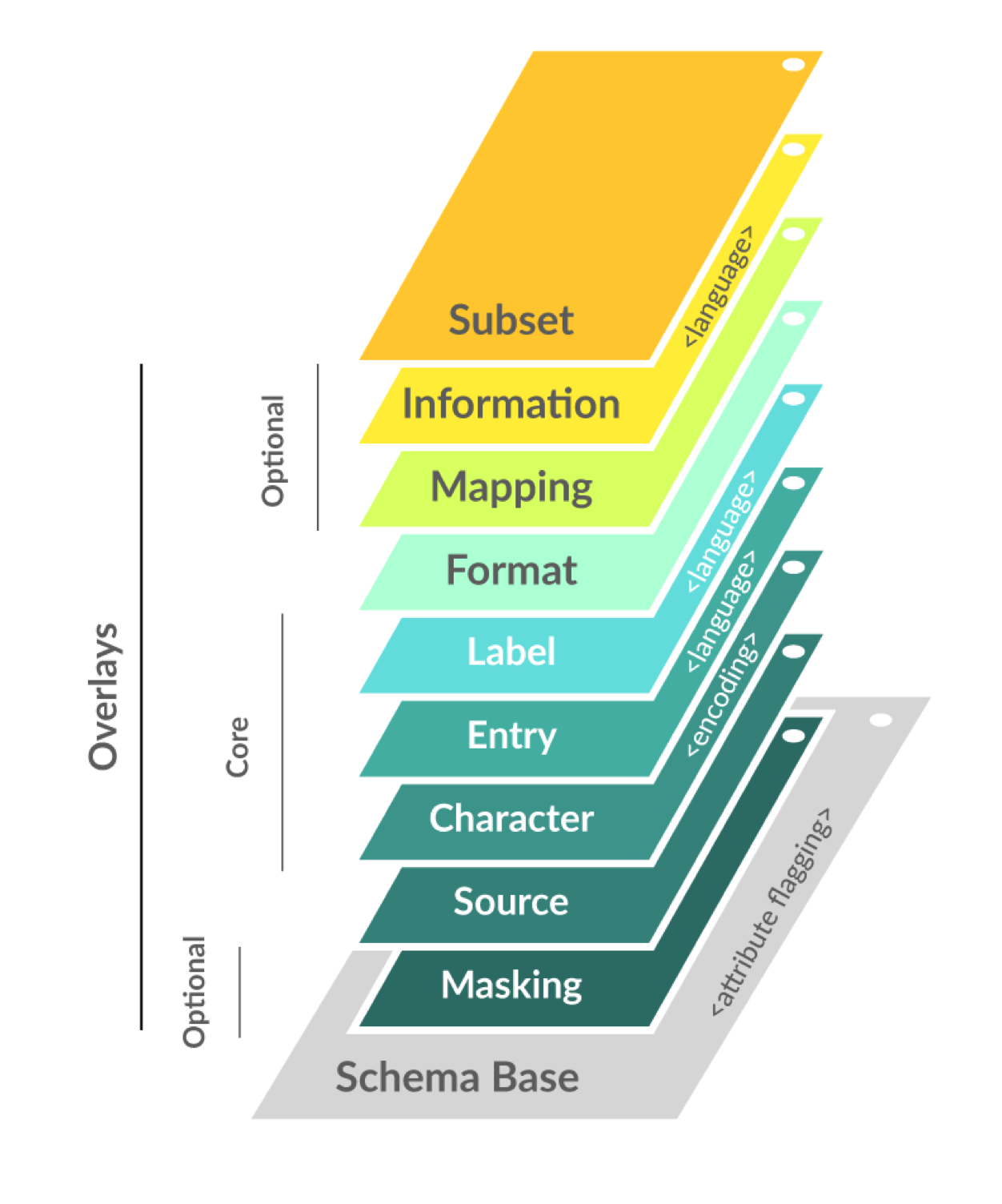
OCA schema bases contain a "blinding_attr" flagging block to enable schema issuers to flag attributes that could potentially unblind the identity of a governing entity.
OCA schema bases contain a "classification" meta attribute to enable industry sector tagging for the purposes of categorization.
OCA resources:
- OCA website - https://oca.colossi.network
- OCA Editor - https://editor.oca.argo.colossi.network
- OCA Repository - https://repository.oca.argo.colossi.network
- OCA source code - https://github.com/thclab
Blinding Identity Taxonomy (BIT)
BIT is a defensive tool created for the purpose of reducing the risk of identifying governing entities within blinded datasets. BIT contains a list of elements to be referred to by schema issuers for flagging attributes which may contain identifying information about governing entities. Once attributes have been flagged, any marked data can be removed or encrypted during the data lifecycle.
- BIT in PDF format: https://docs.kantarainitiative.org/Blinding-Identity-Taxonomy-Report-Version-1.0.pdf
- BIT in HTML format: https://docs.kantarainitiative.org/Blinding-Identity-Taxonomy-Report-Version-1.0.html
Functionality requirements
- Including desired capabilities that a fully interoperable data capture architecture should offer