Meeting Date
The DMRWG meets bi-weekly on Tuesdays at 12:00-13:00 PT / 16:00-17:00 UTC. Check the ToIP Calendar for meeting dates.
Zoom Meeting Link / Recording
- Recording of Meeting
Attendees
Main Goal of this Meeting
TBD
Agenda Items and Notes (including all relevant links)
| Time | Agenda Item | Lead | Notes |
| 5 min |
| Chairs |
|
| 5 mins | Announcements | TF Leads | News or events of interest to WG members:
|
| 20 mins | Possible general solutions to modeling data across multiple schemas (including multiple standards) | All | Nov 29, 2022, meeting featured a presentation by Burak Serdar included a medical data transformation system which is based on work by a number of US Medical Data groups and projects which had created a model (OMOP) which allows data extraction and transformation from data sets using multiple "concrete" schema standards (e.g., standard relational DB schemas) without having to resort to "YAS" yet another standard. As a base to understand today's discussion, it is suggested to review the recording and the materials listed (repeated here):
The approach used was to build a common model which abstracts data across standard schemas into a few high-level "concepts", which allows the grouping of related data into a row-based vs. column-based approach. A column-based (typical relational DB) approach is that each type and variation of personal data, medical measurements, conditions, and observations is a separate column in one or more record types. A row-based approach has a simplified structure that allows differences in measurement types and categories to become a small number of "self-describing" metadata columns that provide type and classification information for the actual data value. Another approach to aid in different language locales was to take any of the data values and, where they were not a numerical value to assign them a discreet index number (integer) such that translation to other languages is a lookup of the index number for that particular language. This approach resulted in over 6,000,000 (yes, 6 million) separate discreet index numbers, categories, and data types. Its advantage is that over time, it has proven that supporting additional medical data standards only adds to the index number values, which doesn't change the abstract/meta-model, showing that in this medical data "ecosystem," the model is stable. This model is more complex to extract data for a particular study (or to transform to a different concrete relational or graph data schema, however, creating multiple pass queries is a well-known approach that can be optimized. The stability of the abstract/meta-model also brings stability to queries built for extraction and transformation. By a multi-pass query, querying an abstract/meta-model requires the first pass to identify the metadata and a second to extra the data specified by that metadata. The promise is to explore this approach as a way of simplifying data exchange in general - in a world dominated by multiple international and local "standards" - for next generation SSI based applications but also to potentially assist in resolving interoperability for Verifiable Credentials within a given Credential Ecosystem (e.g., academic, medical). Good Health Pass as a POC - As a project to explore this technique, it was suggested to revisit the Good Health Pass project, which was developed in 2020 as the COVID crisis was exploding and impeding travel across international borders. The project ultimately did not achieve its goal of producing a "health pass" related to COVID, designed to be universally acceptable by each country. This project did not succeed in being accepted, in part due to the inability of countries around the world to cooperate in defining a single acceptable set of claims and credentials for COVID-related travel and a set of common evaluation rules (and common rules evaluation engine) to determine if a traveler met a given national health standard for entry into that country. This was understandable as a travel solution was required almost immediately, so an attempt at an international agreement was quickly abandoned. The goal of the project (possibly as a Task Force) is
|
| 5 mins | Trust Registry issues in Academia | All | Carly provided some insight into the academic domain on potential issues for "authentic data", particularly for provenance to all the human individuals involved in collecting, processing, governing, and publishing the data, as well as academic papers based on the data. Data collected by (grad (Masters, PhD) students is assigned to a student by the academic institution identity and possibly their own personal identity (but possibly only indirectly). The same is also true of the range of positions within post-graduate studies, including various levels of researchers (from "teaching assistants" to full-tenured professors). Post-grad students (like employees in many organizations) are only there for a short time, yet they may be involved with data, where they are cryptographically signing the data in one of several roles. That data may be used for many years, where the student/employee has moved on from their role at the university/employer, yet a user of the data may be looking to establish the quality of the data based on the reputation of the people involved in the all the steps in processing the data. Over time the problem (in a distributed network) becomes where does that (now inactive) information on signatories to the authentic data change is stored and how can it be found - both of which are currently understood to be responsibilities of trust registries and their relationship with "authentic" objects (identities, VCs, and general data, including medical records), which have yet to be defined. |
| 5 mins |
| Chairs | Line up topics and presentations for meetings in 2023 |
Screenshots/Diagrams
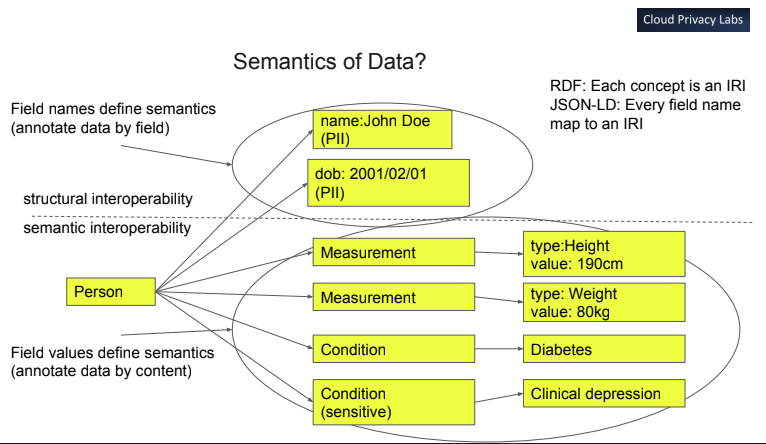
An illustration of taking concrete "column data" (e.g. each Measurement,
Condition or Person data type is defined as a data column) which are
categorized in a "row data" model where the category and and type of data are
"self-describing" metadata rows in columns in the meta/abstract tables using the
model below.
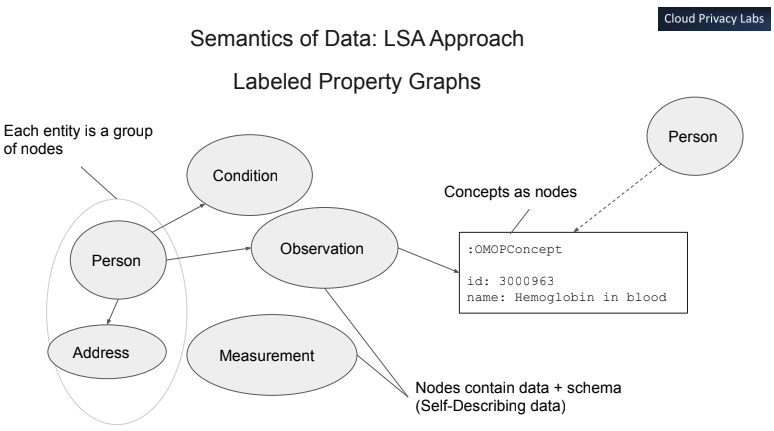
The underlying "meta/abstract" model derived from multiple medical data
standards for data exchange in the OMOP model
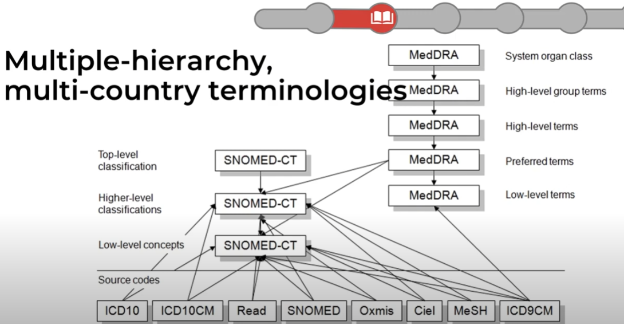
OMOP model - how multiple standards and terms (terminologies) can be
combined in a single "meta/abstract" model that allows the extraction of data
from multiple standards in a scalable way