Meeting Date
Attendees
- Drummond Reed
- Rieks Joosten
- Daniel Hardman
- Brian Dill
- RJ Reiser
Main Goal of this Meeting:
To update CTWG members on the tooling and process discussed at the last meeting and agree on the workplan going forward in January.
Agenda
| Time | Item | Lead | Notes |
| 1 min | Welcome & Antitrust Policy Notice | Chairs | |
| 2 mins | Introduction of new members | Chairs | |
| 1 min | Agenda review | Chairs | |
| 30 mins | Report on tooling and process planning meetings | ||
| 20 mins | Discuss workplan going forward in Q1 | All | |
| 2 mins | Review of Decisions and Action Items | Chairs | |
| 1 min | Next meeting | Chairs |
Recording
- No recording was made of this meeting
Presentation(s)
Notes
- New members
- White papers and using hover links that produce a pop-up
- This works the same way as Wikipedia - rich text and graphics but still constrained
- All of those in attendance on this call were in favor of doing this
- Daniel Hardman pointed out that there may be challenges about what part of the definition shows up in the pop-up
- Rieks would like to use a paper we are the authors of to flesh out the specifications—he suggests starting with the proposed Decentralized SSI Governance paper—or one of the Sovrin Governance documents
- Report on tooling and process planning meetings
- Daniel Hardman and Dan Gisolfi met and have some new thoughts
- Daniel Hardman and Rieks Joosten met last week and ended out refining the thinking about process
- Daniel Hardman shared his takeaways and recommendations in this slide deck
- See the Data Lifecycle slide below for the process overview
- He showed an example of the ingested form of the data (a proposed definition of the term "Agent"). The ingested form is not normalized.
- In the second stage, the data is normalized using a script (that should be fairly easy)
- It separates terms from concepts
- Terms are cross-linked to concepts
- This can solve many issues, including multi-lingual terms, multiple terms for the same concept, etc.
- We discussed issues around multiple terms for the same concept
- In the same language
- In different languages
- Rieks pointed out that all definitions should be provided within contexts (also called scopes or vocabularies)
- In the third stage, we "glue them all back together", but we will include metadata that explains what the CTWG knows about the term
- Edit history
- Term status
- Comments
- Daniel wanted to see if we had overall consensus on the three forms of data (ingest, curate, produce) as show in the Data Lifecycle diagram below. YES.
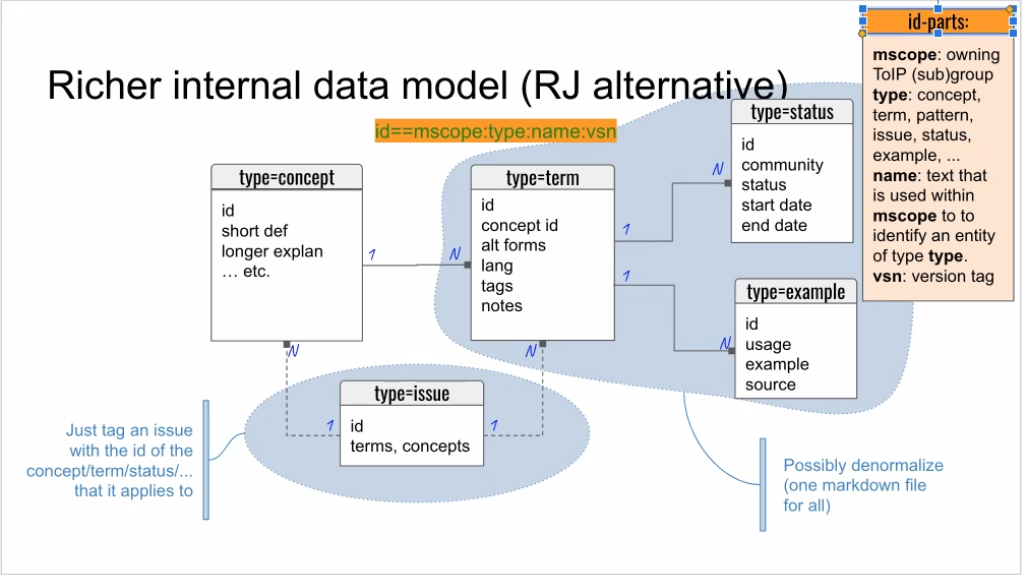
- Rieks then reported on a richer internal data model (see second slide below)
- This allows extensibility of the internal data model to meet more needs over time
- The id of a type=term can be a text string
- This should future-proof the model
- Daniel noted that the hyperlinks to the corpus are important. There are two kinds of hyperlinks that are needed:
- One is an absolute reference to the corpus as a whole
- The other is a cross-reference within a specific output document
- Rieks made the distinction between links between terms and concepts in vocabularies and in specific documents
- We agreed that hyperlinks to vocabularies and terms within vocabularies
- We discussed the actual structure of the hyperlinks and using git artifacts and metadata for the links
- One particular question is version identifiers: do we need human-friendly version identifiers OR git commit hashes OR both?
- We discussed these two options and their respective advantages
- The git commit hash is "cheap" but not human-friendly.
- Rieks suggested that git commits can also have tags.
- Daniel liked the idea of tags for the human-friendly portion.
- Daniel raised the issue of forks and branches—which is why git uses commit hashes.
- Rieks noted that their are indeed good use cases for forking a terminology repo, including personal glossaries, or handing off authority for a terminology.
- Workplan going forward
- We did not have time for this topic
- Review of Decisions and Action Items
- See below
- Next meeting
- Regular time on 4 January 2021
Slides

Decisions
- We will follow the three stages of data (ingest, curate, produce) shown in the Data Lifecycle diagram above.
Action Items
- Rieks Joosten will propose the URL syntax for hyperlinking into the CTWG corpus by
- Daniel Hardman will draft the script for processing ingest entries into the normalize form for curation by