The contents of this page is work in progress and subject to discussion and changes.
Working with terminologies is shown in the figure below:
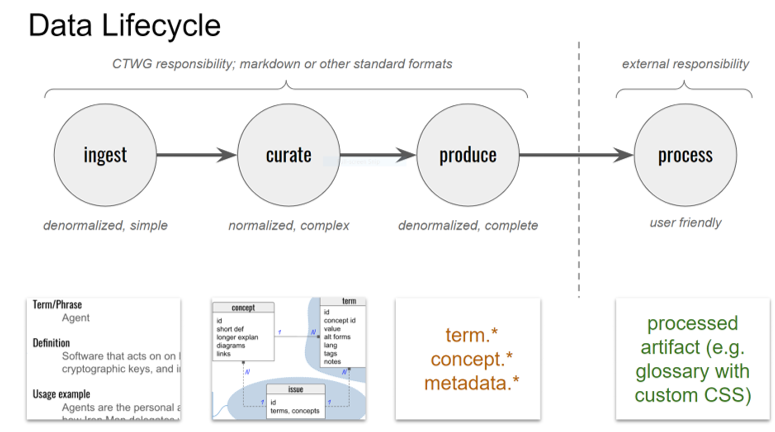
Where:
INGEST
is a stage that contains contents of various kinds that authors can produce even if they have have limited or no technical working knowledge, such as your average business person, lawyer, etc. The kinds of contents that authors may submit would be limited to a set of predefined (markdown) document templates, with or without a header construct (as e.g. in Docusaurus). Any submission of a certain kind (template) will be processed according to the mechanisms specified for that template, unless the input cannot be processed (invalid input). The output of such processing typically is content that is added to the CURATE state, but other outputs could be created if that is beneficial.
To be discussed:
- the kinds of document templates that authors may use to submit contents;
- for each of such kinds: the criterion for determining whether or not it valid for further processing;
- the specification of such processing, i.e. what parts of the contents go where in the curate stage (or elsewhere).
- ,,,
CURATE
is a stage that contains all sorts of typed, normalized contents. 'Normalized' means that there is no duplication of content, and all content can be identified by a single identifier. 'Typed' means that files may contain different contents, e.g. a description of a concept, the definition of a term, etc.
Every such file will be owned/curated by (one or more designated participants of) a ToIP group. Curators make decisions about the contents of a file, whether or not to update it, etc. They are responsible for the quality of the contents. They need appropriate permissions to do so. A history of changes is kept that allows older content to be referenced continuously.
All curation content (the 'Corpus') is stored in a directory, with a subdirectory for each owner (curator), in which we will see further subdirectories for the various types of contents. Each file can thus be identified by the tuple (owner,type,filename), or by `https://toip.org/ctwg/corpus/owner/type/filename` or similar. A person that is a curator for an owner (ToIP group) is assigned appropriate permissions for everything under //toip.org/ctwg/corpus/owner/. We expect to use git(hub) to manage the corpus.
The purpose of curation content is for it to be used in the PRODUCE stage, which means that the structure of each kind of file must be defined such that it is fit for any/all of the purposes that this PRODUCE stage serves. This requirement may impose constraints on the internal structure of the different kinds of files in the corpus.
A curated file has a header that specifies its owner, type, name and version (there may be a mapping between 'name' and the filename of the file, e.g. filename == 'name'+'_'+'version'), e.g. as:
==========
owner: "ToIP CTWG"
type: "concept"
name: "actor"
vsn: "2"
==========
Other header entries may be defined, as needed (e.g. an entry that specifies text to be used as a popover, or as a glossary entry, or ....).
Versioning needs to be discussed. While from a tech perspective it is beneficial to use github commits as a version, this may not be suitable for authors that want to refer to an element in the Corpus.
PRODUCE
is a stage in which all sorts of documentary artifacts are being created/generated/... We expect to see this stage produce glossaries in various renderings (web, pdf, ...), dumps of (parts of) the Corpus (e.g. a JSON or XML file), etc. The CTWG will cater for a minimal set of artifacts to be produced, such as a ToIP Dictionary, and a default glossary of terms for every owner. Depending on the needs we encounter, other artifacts may also be produced. Specifically, we expect one or two artifacts to be produced that allow third parties to do further processing on the contents of the Corpus. While the production of such artifacts is within CTWG scope, the further processing is an external responsibility.
Every artifact that is produced must have a 'definition document', i.e. a machine processable specification that allows the artifact to be automatically created, either on demand (of a user), or as a result of a trigger firing (such as the acceptance of a pull request). We may want to ponder the idea of including a file-type "artifact definition document" as one of the accepted file-types in the Corpus.